论文笔记:Linear Attention Mechanism: An Efficient Attention for Semantic Segmentation
由于经典的 Dot product Attention 具有较大的空间和时间复杂度,虽然效果很好,但由于图像和视频输入的数据量经常比文字大很多,这种经典的 Attention 限制了在高分辨率图像中的应用。本文提出了一种线性的 Attention 模块,希望能够解决这样的问题同时在性能上不会有明显的损耗。
本文主要贡献点有:
1)提出了一种新的线性化 Attention 方式,能够将计算复杂度从 \(𝑂(𝑁^2)\) 降低到 \(𝑂(𝑁)\)
2)该 Attention 机制使得 Attention 与网络的结合更加通用和灵活;
3)在语义分割任务中,该 Attention 机制的引入在多种 baseline 上获得了性能提升。
1 METHODOLOGY
A. Definition of Dot-Product Attention
给定一个输入的特征向量 \(X=\left[\boldsymbol{x}_{1}, \cdots, \boldsymbol{x}_{N}\right] \in \mathbb{R}^{N \times D_{x}}\),其中 \(N\) 代表特征长度,\(D_x\) 代表特征维度。那么 Dot-Product Attention 通过点乘变换矩阵 \(\boldsymbol{W}_{q} \in \mathbb{R}^{D_{x} \times D_{k}}\)、\(\boldsymbol{W}_{k} \in \mathbb{R}^{D_{x} \times D_{k}}\) 以及 \(\boldsymbol{W}_{v}= \mathbb{R}^{D_{x} \times D_{v}}\) 分别生成 Query Matrix,Key Matrix 和 Value Matrix ,其公式如下:
\(\begin{aligned}
&\boldsymbol{Q}=\boldsymbol{X} \boldsymbol{W}_{q} \in \mathbb{R}^{N \times D_{k}} \\
&\boldsymbol{K}=\boldsymbol{X} \boldsymbol{W}_{k} \in \mathbb{R}^{N \times D_{k}} \\
&\boldsymbol{V}=\boldsymbol{X} \boldsymbol{W}_{\boldsymbol{v}} \in \mathbb{R}^{\boldsymbol{N} \times \boldsymbol{D}_{v}}
\end{aligned}\tag{1}\)
其中 Q 和 K 的维度必须相同。
在此基础上,引入一个归一化函数 \(\rho\) 来度量 \(\boldsymbol{q}_{i}^{T} \in \mathbb{R}^{D_{k}}\) 和 \(\boldsymbol{k}_{j} \in \mathbb{R}^{D_{k}}\) 的相似度 \(\rho\left(\boldsymbol{q}_{i}^{T} \boldsymbol{k}_{j}\right) \in \mathbb{R}^{1}\)。而 Scaled Dot-Product Attention 就是相当于以 \(\rho\left(\boldsymbol{q}_{i}^{T} \boldsymbol{k}_{j}\right) \in \mathbb{R}^{1}\) 为权重对 \(v_j\) 做加权平均。Dot-Product Attention 对于整个矩阵的定义如下:
\(D(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})=\rho\left(\boldsymbol{Q} \boldsymbol{K}^{T}\right) \boldsymbol{V}\tag{2}\)
其中最常用的一种归一化函数就是 softmax:
\(\rho\left(\boldsymbol{Q}^{T} \boldsymbol{K}\right)=\operatorname{softmax}_{\text {row }}\left(\boldsymbol{Q} \boldsymbol{K}^{T}\right)\tag{3}\)
对于 \(\boldsymbol{Q} \in \mathbb{R}^{N \times D_{k}}\) 和 \(\boldsymbol{K}^{T} \in \mathbb{R}^{D_{k} \times N}\) ,\(\boldsymbol{Q}\boldsymbol{K}^{T} \in \mathbb{R}^{N \times N}\) 因此 \(\rho\) 的时间和空间复杂度均为 \(𝑂(𝑁^2)\)。
B. Generalization of Dot-Product Attention Based on Kernel
基于 Kernal 对 Dot-Product Attention 进行一般化定义。对于 softmax 形式归一化函数来说,可以写成:
\(D(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})_{i}=\frac{\sum_{j=1}^{N} e^{\boldsymbol{q}_{i}{ }^{T} \boldsymbol{k}_{j}} \boldsymbol{v}_{j}}{\sum_{j=1}^{N} e^{\boldsymbol{q}_{i}{ }^{T} \boldsymbol{k}_{j}}}\tag{4}\)
\(e^{\boldsymbol{q}_i^{\top}\boldsymbol{k}_j}\) 就是对于 \(v_j\) 做加权平均的权重, 该公式可以更进一步一般化定义为:
\(\begin{gathered}
D(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})_{i}=\frac{\sum_{j=1}^{N} \operatorname{sim}\left(\boldsymbol{q}_{i}, \boldsymbol{k}_{j}\right) \boldsymbol{v}_{j}}{\sum_{j=1}^{N} \operatorname{sim}\left(\boldsymbol{q}_{i}, \boldsymbol{k}_{j}\right)} \\
\operatorname{sim}\left(\boldsymbol{q}_{i}, \boldsymbol{k}_{j}\right) \geq 0
\end{gathered}\tag{5}\)
显然当定义 \(\operatorname{sim}\left(\boldsymbol{q}_{i}, \boldsymbol{k}_{j}\right)=e^{\boldsymbol{q}_{i}{ }^{T} \boldsymbol{k}_{j}}\) 时,该式和标准 softmax 的 Attention 公式等价。这种形式的 Attention 在 CV 中一般也称作 Non-Local 网络。
显然如果直接去掉指数定义 \(\text{sim}(\boldsymbol{q}_i, \boldsymbol{k}_j) = \boldsymbol{q}_i^{\top}\boldsymbol{k}_j\) 不满足非负性质,为了完成这一点可以考虑加入核函数,更改定义为:
\(\text{sim}(\boldsymbol{q}_i, \boldsymbol{k}_j) = \phi(\boldsymbol{q}_i)^{\top} \varphi(\boldsymbol{k}_j)\tag{6}\)
那么 Attention 公式又可以重新定义为:
C. Linear Attention Mechanism
与之前很多线性化的方式不同,本文利用一阶泰勒展开来进行线性化:
\(e^{\boldsymbol{q}_{i}^{T} \boldsymbol{k}_{j}} \approx 1+\boldsymbol{q}_{i}{ }^{T} \boldsymbol{k}_{j}\tag{8}\)
为了保证 \(\boldsymbol{q}_{i}{ }^{T} \boldsymbol{k}_{j} \geq-1\) 我们将 \(\boldsymbol{q}_{i}\) 和 \(\boldsymbol{k}_{j}\) 进行 l2 norm:
\(\operatorname{sim}\left(\boldsymbol{q}_{i}, \boldsymbol{k}_{j}\right)=1+\left(\frac{\boldsymbol{q}_{i}}{\left\|\boldsymbol{q}_{i}\right\|_{2}}\right)^{T}\left(\frac{\boldsymbol{k}_{j}}{\left\|\boldsymbol{k}_{j}\right\|_{2}}\right) .\tag{9}\)
则 Attention 公式又可以重写为:
\(D(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})_{i}=\frac{\sum_{j=1}^{N}\left(1+\left(\frac{\boldsymbol{q}_{i}}{\left\|\boldsymbol{q}_{i}\right\|_{2}}\right)^{T}\left(\frac{\boldsymbol{k}_{j}}{\left\|\boldsymbol{k}_{j}\right\|_{2}}\right)\right) \boldsymbol{v}_{j}}{\sum_{j=1}^{N}\left(1+\left(\frac{\boldsymbol{q}_{i}}{\left\|\boldsymbol{q}_{i}\right\|_{2}}\right)^{T}\left(\frac{\boldsymbol{k}_{j}}{\left\|\boldsymbol{k}_{j}\right\|_{2}}\right)\right)}=\frac{\sum_{j=1}^{N} \boldsymbol{v}_{j}+\left(\frac{\boldsymbol{q}_{i}}{\left\|\boldsymbol{q}_{i}\right\|_{2}}\right)^{T} \sum_{j=1}^{N}\left(\frac{\boldsymbol{k}_{j}}{\left\|\boldsymbol{k}_{j}\right\|_{2}}\right) \boldsymbol{v}_{j}^{T}}{N+\left(\frac{\boldsymbol{q}_{i}}{\left\|\boldsymbol{q}_{i}\right\|_{2}}\right)^{T} \sum_{j=1}^{N}\left(\frac{\boldsymbol{k}_{j}}{\left\|\boldsymbol{k}_{j}\right\|_{2}}\right)}\tag{10}\)
使用向量形式的写法:
其中 \(\sum_{j=1}^{N}\left(\frac{\boldsymbol{k}_{j}}{\left\|\boldsymbol{k}_{j}\right\|_{2}}\right) \boldsymbol{v}_{j}^{T}\) 和 \(\sum_{j=1}^{N}\left(\frac{\boldsymbol{k}_{j}}{\left\|\boldsymbol{k}_{j}\right\|_{2}}\right)\) 均可以预先计算,并在在每个 query 进行重用。
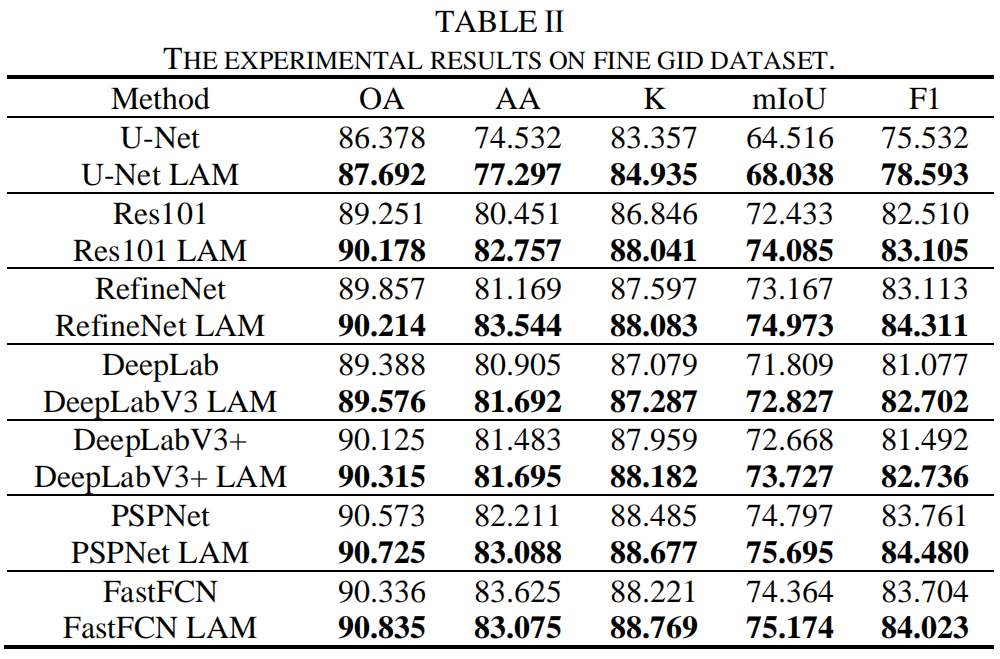
2 EXPERIMENTAL RESULTS
作者在常见的几类图像分割框架中引入本文提出的 Linear Attention,得到了相比基线均能够涨点的结果,说明了本文提出的结构具有普适的有效性。
论文 & 源码
论文
1636966378-Linear Attention Mechanism- An Efficient Attention for Semantic Segmentation
源码
https://github.com/lironui/Linear-Attention-Mechanism
https://github.com/lironui/MAResU-Net
https://github.com/lironui/MACU-Net
参考文献
[1] https://kexue.fm/archives/7546
