论文笔记:Learning to Solve Nonlinear Least Squares for Monocular Stereo
本文利用端对端的网络处理直接法单目 SLAM 问题。作者在多个数据集和问题上实验,最后结果在准确性,参数量和速度上都超过LM方法。虽然整篇文章用于解决单目稠密SLAM问题,不过由于是在整个框架中优化后端的非线性最小二乘部分,其思想对于SLAM问题引入Learning具有普适性。与BA-Net 比较类似,是用深度学习改进后端优化的最基础贡献之一。
本文主要创新点如下:
1)提出了基于非线性最小二乘优化的一个端到端训练的框架;
2)先验和正则项学习都直接来自于训练数据;
3)第一个采用机器学习来优化光度误差的算法。
1 背景
本文背景比较类似于基于优化问题的直接法。
1.1 非线性最小二乘求解(Nonlinear Least Squares Solvers)
典型的非线性最小二乘问题如下:
\(E=\frac{1}{2} \sum_{j} r_{j}^{2}(\mathbf{x})\tag{1}\)其中 \(r_{j}\) 代表第 j 项的误差;\(\mathbf{x}\) 是优化变量;\(E\) 代表目标函数。
通常求解这样的问题会采用数值优化的方法,例如 Gauss-Newton (GN)、Levenberg-Marquadt (LM) 算法等。
通常的做法是将误差进行一阶展开:
\(\mathbf{r}\left(\mathbf{x}_{i}+\Delta \mathbf{x}_{i}\right) \approx \mathbf{r}_{i}+\mathbf{J}_{i} \Delta \mathbf{x}_{i}\tag{2}\)其中:
\(\mathbf{r}_{i}=\mathbf{r}\left(\mathbf{x}_{i}\right), \quad \mathbf{J}_{i}=\left.\frac{d \mathbf{r}}{d \mathbf{x}}\right|_{\mathbf{x}=\mathbf{x}_{i}}\tag{3}\)则最优迭代值为(使得当前误差函数取极小的迭代迭代方向):
\(\Delta \mathbf{x}_{i}=\underset{\Delta \mathbf{x}_{i}}{\arg \min } \frac{1}{2}\left\|\mathbf{r}_{i}+\mathbf{J}_{i} \Delta \mathbf{x}_{i}\right\|^{2}\tag{4}\)在 Gauss-Newton (GN) 法中迭代步长通过下述方程求解:
\(\mathbf{J}_{i}^{T} \mathbf{J}_{i} \Delta \mathbf{x}_{i}=-\mathbf{J}_{i}^{T} \mathbf{r}_{i}\tag{5}\)而与 GN 算法不同,Levenberg-Marquadt (LM) 算法引入 \(p\) 改善收敛性,其迭代步长为:
\(\Delta \mathbf{x}_{i}=-\left(\mathbf{J}_{i}^{T} \mathbf{J}_{i}+\lambda \operatorname{diag}\left(\mathbf{J}_{i}^{T} \mathbf{J}_{i}\right)\right)^{-1} \mathbf{J}_{i}^{T} \mathbf{r}_{i}\tag{6}\)以上是典型的通过梯度下降迭代优化最小二乘问题的步骤。
1.2 映射与光度误差
三维空间中的变换矩阵可以通过 SE(3) 李群中的指数映射得到,其中 \(\) 是对应的李代数:
\(\hat{T}_{t \rightarrow s}=\exp \left(\mathbf{p}^{\times}\right)\tag{7}\)
其投影映射关系如下(极线约束),其中 \(p_{s}\) 代表 source 图中的点坐标,\(p_{t}\) 代表 target 图中的对应点坐标:
通过映射获得光度误差为:
\(L=\sum_{p}\left\|I_{t}(p)-\hat{I}_{s}(p)\right\|_{2}\tag{9}\)其中 \(\hat{I}_{s}(p)\) 通过双线性插值得到。通过建立光度误差:
\(\mathbf{r}_{p}=I_{t}(p)-\hat{I}_{s}(p)\tag{10}\)
其雅克比很容易通过各种框架的 autodiff 自动求导得到(导数包含了双线性差值部分),例如 Tensorflow 里面可以用 tf.gradients(res[i],x)) ,这里无需给出。
2 LS-Net 模型设计
这一部分主要包含三个模块,分别说明如下。
2.1 Initialization Network
这一部分主要是特征提取,作者使用了3个卷积层,stride=2,作为 backbone。最后接一个 upsample 和 conv1x1 得到一个大小为原图的1/4 的输出作为 depth 估计。另外通过 backbone 接全连接层输出一个6维向量作为 pose。这一部分没有什么特别的。
为了能够更好地描述较远的深度,实际上网络输出作者采用的是逆深度形式 \(z=\frac{1}{d}\)。
2.2 Optimizing Nonlinear Least Squares with LS-Net
这一部分就是非线性优化层了,作者称之为 LS-Net。它的算法部分流程如下:

如之前所述,我们要估计的目标函数是上述每个像素的光度误差之和,其中待估计变量分为逆深度z和姿态pose两部分 \(\mathbf{x} = (\mathbf{z}, \mathbf{p})\):
\(E(\mathbf{x})=\frac{1}{2}\|\mathbf{r}(\mathbf{x})\|^{2}\tag{11}\)还是按照一个典型的梯度下降过程:
\(\mathbf{x}_{i+1}=\mathbf{x}_{i}+\Delta \mathbf{x}_{i}\tag{12}\)在本文中最大的不同就是将其中的步长 \(\Delta x_i\) 的估计使用一个循环神经网络(LSTM-RNN)来完成。公式如下:
\(\left[\begin{array}{c}\Delta x_{i} \\
h_{i+1}
\end{array}\right]=\operatorname{LSTM}_{c e l l}\left(\Phi\left(\mathbf{J}_{i}, \mathbf{r}_{i}\right), h_{i}, \mathbf{x}_{i} ; \theta\right)\tag{13}\)
其中 \(\theta\) 是网络的参数,\(h_{i}\) 代表隐藏层。这是一个典型的 LSTM Cell。其中输入部分 \(\Phi\left(\mathbf{J}_{i}, \mathbf{r}_{i}\right)\) 在下一小节介绍。
2.3 The Jacobian input structure
在优化过程中作者遵循 GN 的优化过程,即 \(\mathbf{J}_{i}^{T} \mathbf{J}_{i} \Delta \mathbf{x}_{i}=-\mathbf{J}_{i}^{T} \mathbf{r}_{i}\),但是本文中的雅克比是通过对深度和姿态的自动求带获得(感觉这一步可能不合理,因为自动求导会当做在欧式空间完成,实际上pose是李代数上的)。为了简化雅克比矩阵,作者按照下图做了进一步变换,将 \(\mathbf{J}_{i}^{T} \mathbf{J}_{i}\) 压缩后作为网络的输入,具体压缩过程如下图所示:
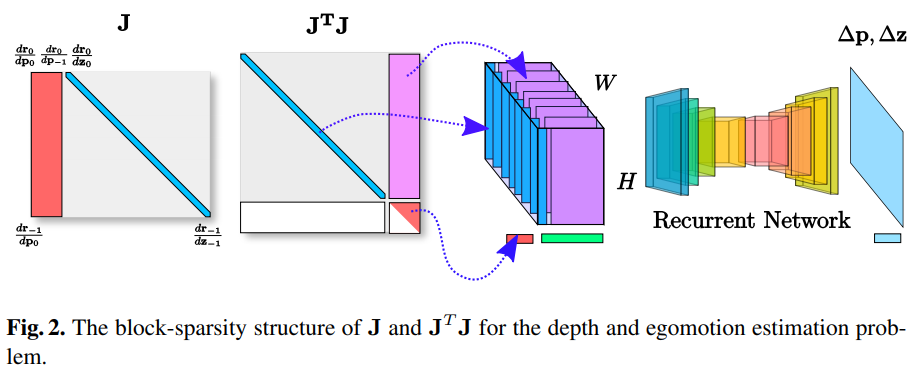
这里也利用了所谓雅克比矩阵的稀疏性,通常 pose 的数量远少于需要估计的深度的数量,所以可以这样压缩。实际上是减少了没用的参数输入,加快网络计算的速度。
压缩后的 \(\mathbf{J}_{i}^{T} \mathbf{J}_{i}\) 和 对应的 \(r_i\) 合起来(concanate)作为 LSTM 的输入:
\(\Phi(\mathbf{J}, \mathbf{r})=\left[\mathbf{J}^{\mathrm{T}} \mathbf{J}, \mathbf{r}\right]\tag{14}\)这里作者避免了使用 \(\left(\mathbf{J}^{T} \mathbf{J}\right)^{-1} \mathbf{J}\) 作为网络输入是因为这里增加了大量计算(而且事实上也没提供新的输入信息)。
2.4 Upscaling Network
上一步的迭代优化网络为第一步初始化网络进行采样后的输入,因此,最后还需要一个上采样网络将优化后的深度图变成原图大小。作者采用的上采样函数就是双线性插值。
3 Loss
网络总计包含两个误差项,深度误差 与 姿态误差,两个 Loss 都是 L1 范数。
其中深度部分误差项定义为:
\(L_{d e p t h}(\mathbf{x})=\frac{1}{w h}\|\mathbf{z}-\tilde{\mathbf{z}}\|_{1}\tag{15}\)姿态部分误差项定义为:
\(L_{\text {pose}}(\mathbf{x})=\sum_{s}\left\|\boldsymbol{\alpha}_{t \rightarrow s}-\tilde{\boldsymbol{\alpha}}_{t \rightarrow s}\right\|_{1}+\left\|\mathbf{t}_{t \rightarrow s}-\tilde{\mathbf{t}}_{t \rightarrow s}\right\|_{1}\tag{16}\)其中的 \(\tilde{\mathbf{p}}=\left(\tilde{\mathbf{t}}_{t \rightarrow s}, \tilde{\boldsymbol{\alpha}}_{t \rightarrow s}\right)\) 包含平移向量 \(\tilde{\mathbf{t}}_{t \rightarrow s}\) 和旋转向量 \(\tilde{\boldsymbol{\alpha}}_{t \rightarrow s}\)。
最终的误差项是二者加权求和:
\(L_{t o t}(\theta)=\sum_{i} w_{p o s e} L_{p o s e}\left(\mathbf{x}_{i}(\theta)\right)+w_{d e p t h} L_{d e p t h}\left(\mathbf{x}_{i}(\theta)\right)\tag{17}\)4 Experiments
实验部分作者做了仿真和实际的实验对比。这里仅简略摘要,详细请看原文。
4.1 仿真数据对比
仿真部分作者做了简单的曲线拟合工作,用来和 LM 算法比较收敛速度以及误差,作者拟合的曲线包含:
\(\begin{array}{c}y=x \exp (a t)+x \exp (b t)+\epsilon \\
y=\sin (a t+b)+\epsilon \\
y=\operatorname{sinc}(a t+b)+\epsilon \\
y=\mathcal{N}(t \mid \mu=a, \sigma=b) \text { (fitting a Gaussian) }
\end{array}\tag{18}\)
得出的实验结果如下图:
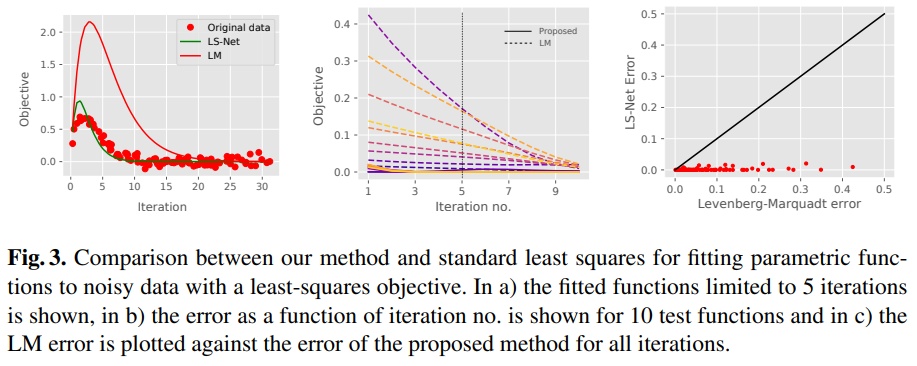
可以看到:
在图 a)中,仅经过5次迭代的话,LS-Net 拟合的曲线明显比 LM 拟合的曲线更接近真值。
在图 b)中,可以看出 LS-Net (实线)比 LM(虚线)收敛速度明显更快。
在图 c)中,将相同迭代次数的 LM 误差(x)和 LS-Net(y)做成散点图,可以看出相同迭代次数的 LM 误差均远大于 LS-Net 误差。说明 LS-Net 的收敛速度和收敛结果都更好。
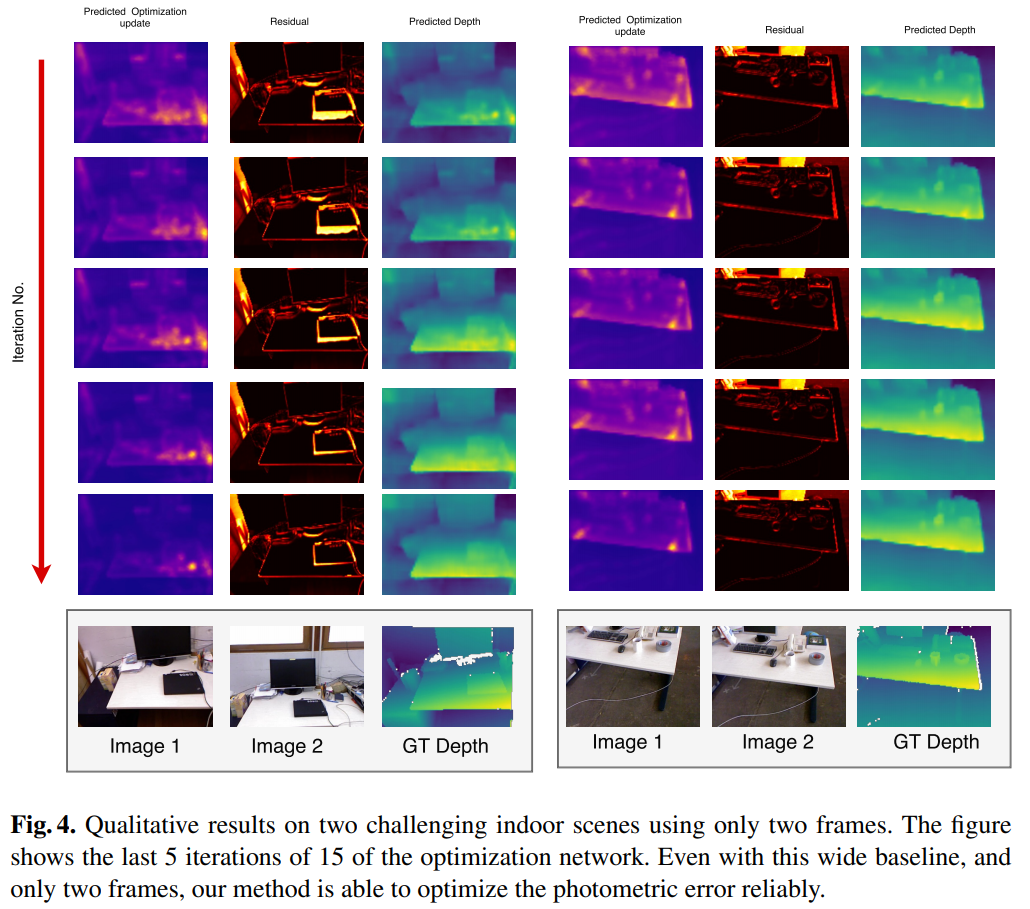
4.2 两幅图像深度估计
作者选取了 2-view 深度估计,证明即使在两幅图相距很远或者很近的极端情况,LS-Net 依然能够估计出可信的深度:
4.3 与 DeMoN 的对比
与同是深度学习方法的 DeMoN 的对比,在一些情况下显示出了更好的性能:

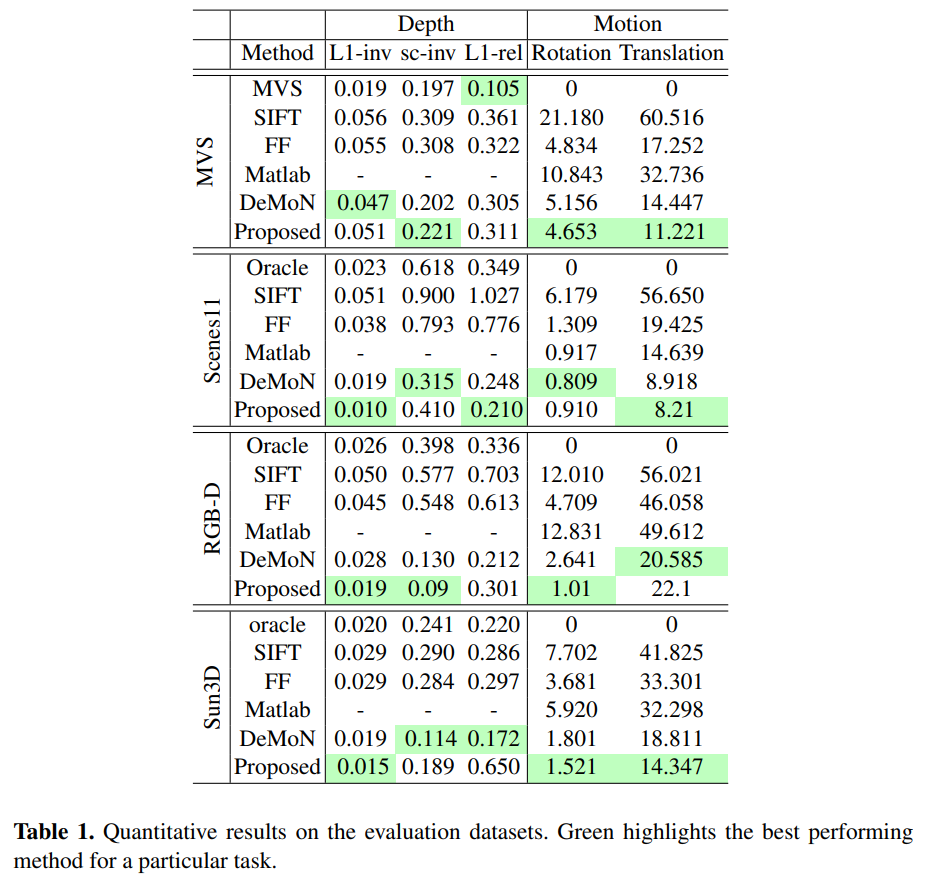
4.4 与其他方法的对比
MVS : uses oracle with known poses
SIFT : uses sparse features for correspondences
FF : uses optical flow
Matlab : uses KLT tracker in Matlab
论文下载
论文:
PPT:
1604908422-05_LS-Net
